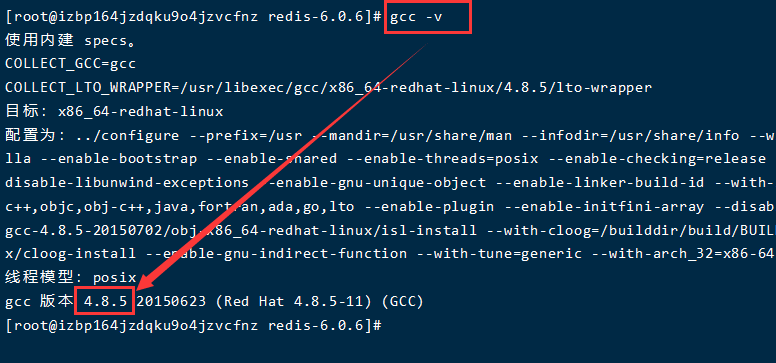
Redis概念及配置方式
Linux下安装步骤
常规安装
wget http://download.redis.io/releases/redis-6.0.6.tar.gztar xzf redis-6.0.6.tar.gzcd redis-6.0.6make- 问题一
make: *** [all] 错误 2![]()
- 问题一原因
- Linux系统gcc版本过低,yum安装的gcc是4.8.5的。需要升级gcc
![]()
- Linux系统gcc版本过低,yum安装的gcc是4.8.5的。需要升级gcc
- 问题一解决
yum -y install centos-release-sclyum -y install devtoolset-7-gcc devtoolset-7-gcc-c++ devtoolset-7-binutilsscl enable devtoolset-7 bash- 注意:scl只是临时启用这个gcc版本,重启就会失效,需要长期使用此版本GCC,需要运行如下命令
echo "source /opt/rh/devtoolset-7/enable" >>/etc/profile
- 重新运行
make
- 问题一

Docker安装
暂无
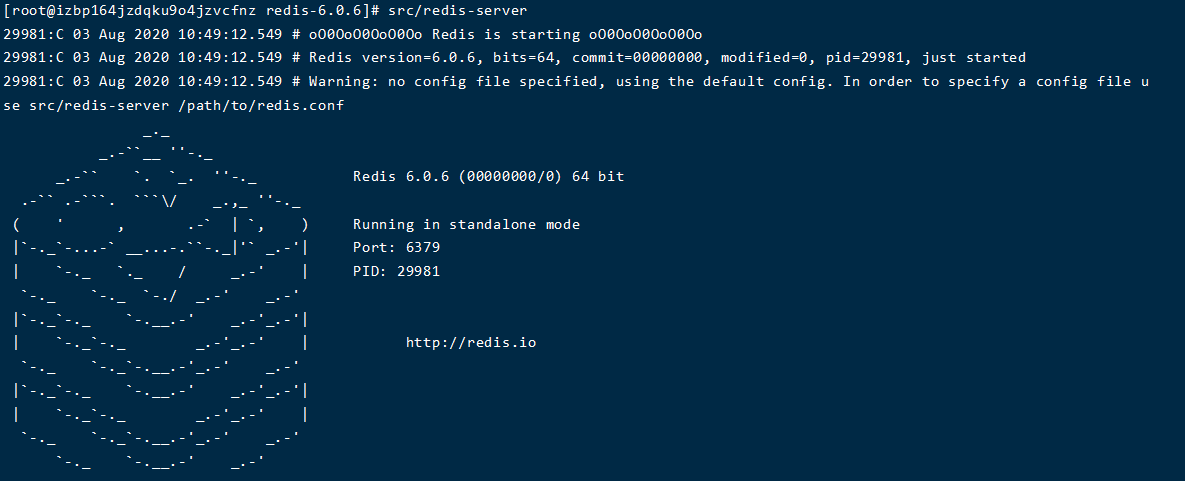
运行
- 确保自己在redis目录下
![]()
- 前台运行
src/redis-server![]()

目录结构

更改配置
配置文件位置
/root/redis-6.0.6/redis.conf- 注意:注意看自己是在哪个目录下进行解压操作的
打开配置文件
vim redis.conf- 注意:vim命令未找到的话,需要安装一下
yum install -y vim(未测试)
- 注意:vim命令未找到的话,需要安装一下
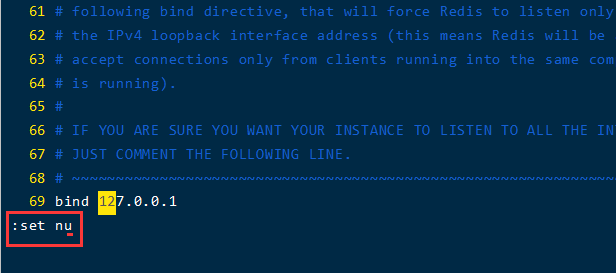
更改redis绑定的IP地址
- 跳转到69行
shift + :,输入69,按enter键,这里建议修改为0.0.0.0,即是允许所有IP地址连接的意思![]()
- 注意:输入命令
set nu可以显示文件行号![]()
- 跳转到69行
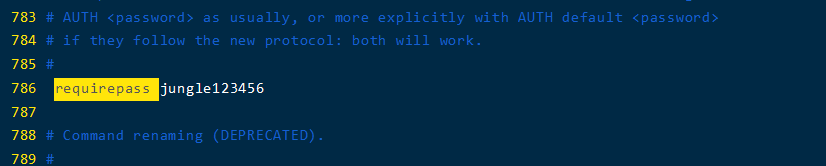
更改密码
- 同上一样,所在行号如下表格所示
![]()
- 注意:在登录时如果不设置密码,将出现权限不足的问题(也可以将
protected-mode设为no解决)
- 同上一样,所在行号如下表格所示

重要几个参数所在行号
| 参数名 | 参数解释 | 所在行号 | 默认值 |
|---|---|---|---|
| bind | 绑定的主机IP地址 | 69 | 127.0.0.1 |
| protected-mode | 是否可以直接访问,开启需配置bind ip或者设置访问密码 | 88 | yes |
| port | 指定Redis监听端口,默认端口为6379 | 92 | 6379 |
| pidfile | 守护进程方式运行时,pid的值 | 244 | /var/run/redis_6379.pid |
| loglevel | 日志级别,有debug、verbose、notice、warning | 252 | notice |
| logfile | 日志文件位置,默认为标准输出, | 257 | “” |
| databases | 逻辑数据库的数量,默认连接数据库为0号数据库,可以使用SELECT |
272 | 16 |
| save | save |
304 | 多个 |
| requirepass | 密码 | 786 | foobared |
- 重启Redis服务
- 找到已运行redis进程号
ps -ef|grep redis- 如果只显示一行,则说明redis没有运行,则不用进行重启
![]()
- 如果只显示一行,则说明redis没有运行,则不用进行重启
- 杀死已启动的进程
kill -9 pid号 - 重新运行
./redis-server /root/redis-6.0.6/redis.conf &,注意在src的目录下!!!![]()
- 三种方式
- 方式一:直接启动,进入redis根目录,执行.
/redis-server &,&代表后台运行- 注意:此方式不会重新加载配置文件
- 方式二:指定配置文件,进入根目录,执行
./redis-server 配置文件名,例如:./redis-server/etc/redis/6379.conf - 方式三:后台自启(略),参考链接
- 方式一:直接启动,进入redis根目录,执行.
- 三种方式
- 检查后台运行是否成功
ps aux|grep redis![]()
- 找到已运行redis进程号



远程连接(需要开放IP及端口)
使用自己的redis连接工具,这里使用的是
RedisView![]()
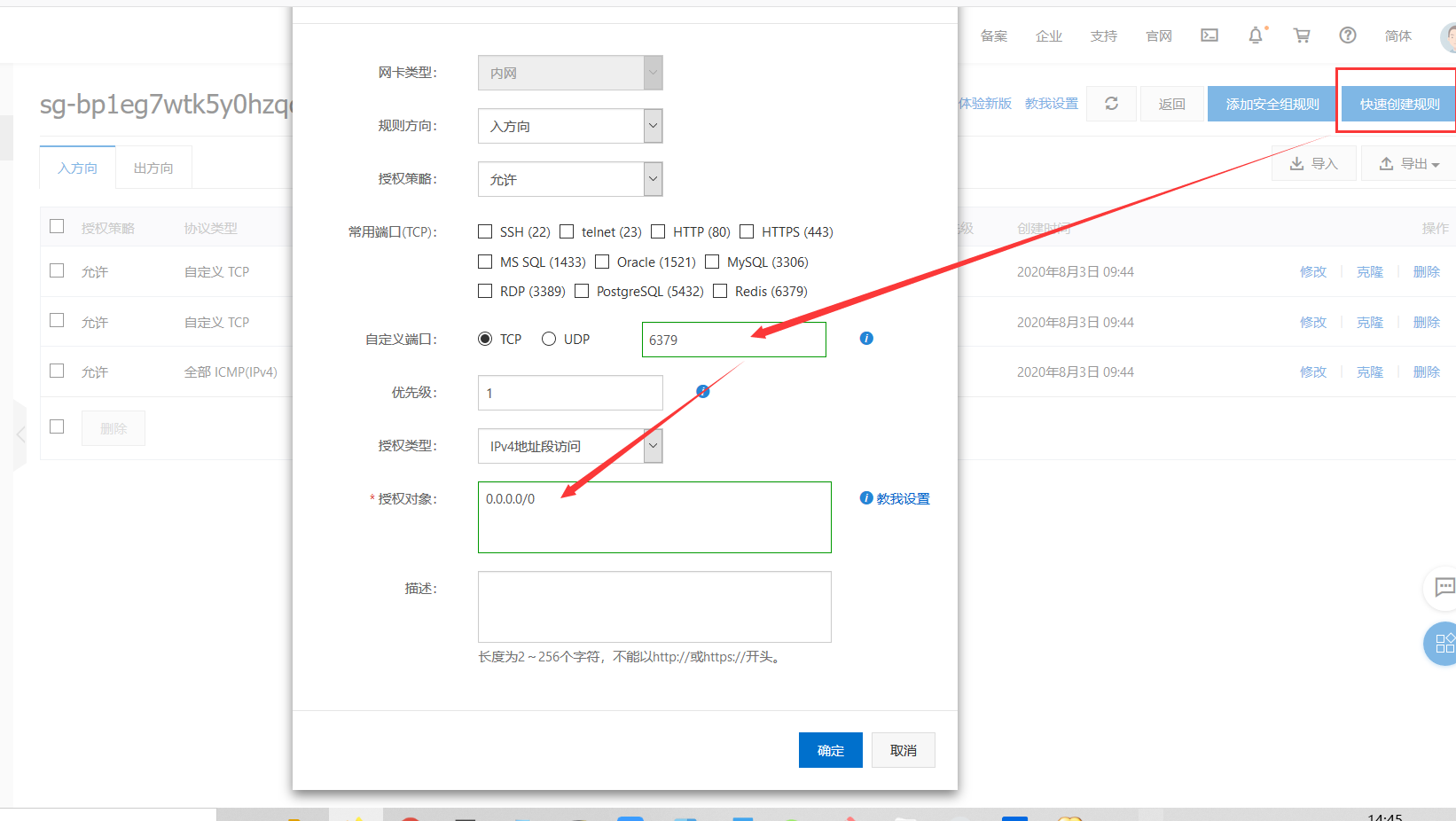
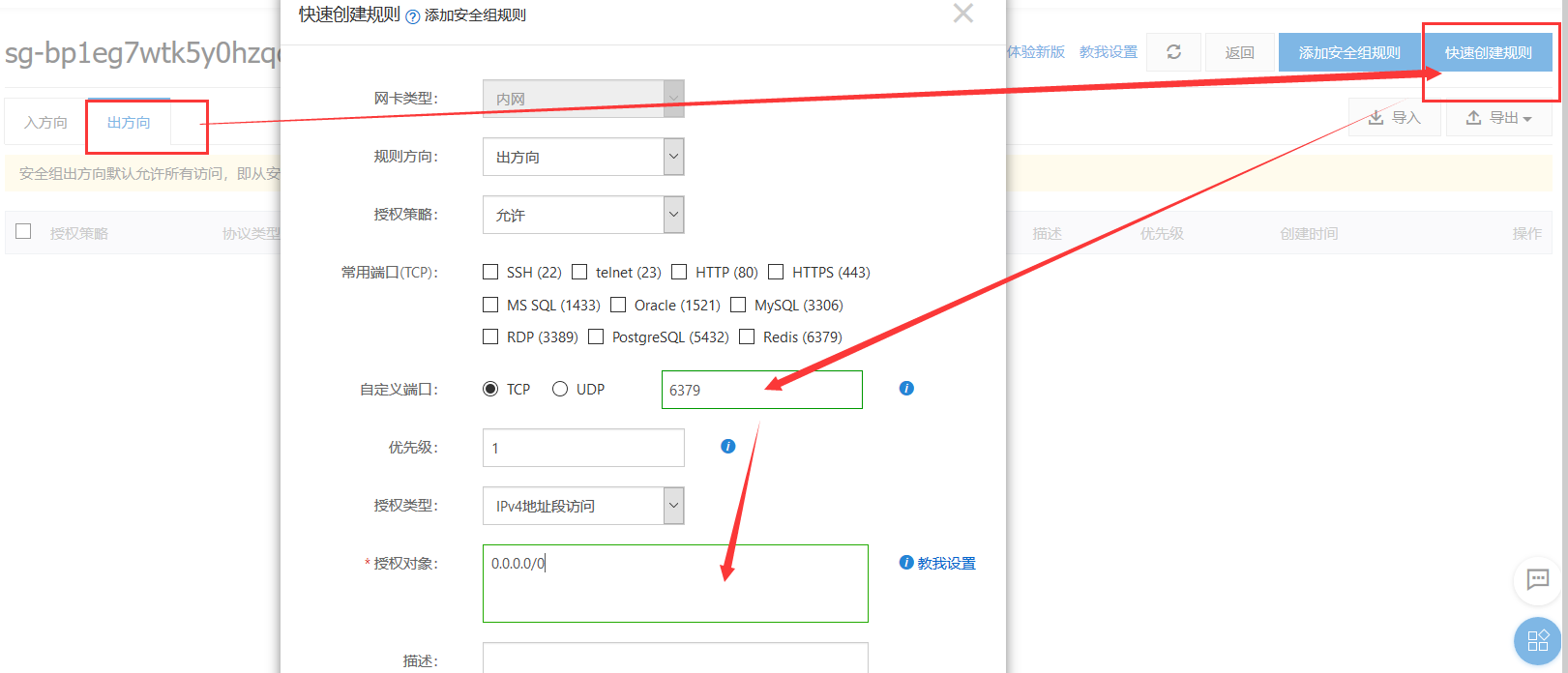
注意:阿里云或者腾讯云等需要开放安全组,也就是防火墙开放远程连接ip和端口
使用redisbin,在windows命令行连接
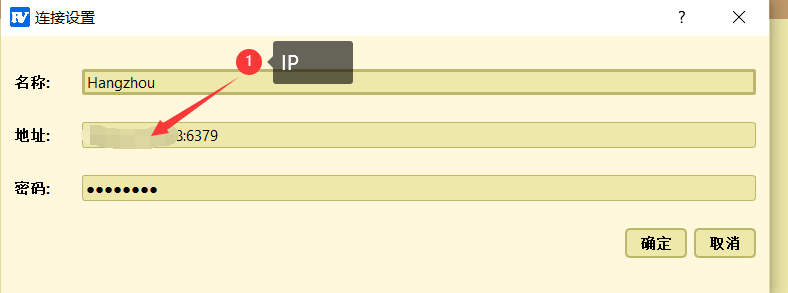

阿里云开放IP及端口

登录成功
数据类型
String存储简单字符串、复杂字符串(xml、json)、数字(整数、浮点数)、二进制(图片、音频、视频),最大不能超过512MHash存储结构化对象List存储字符串类型的集合数据,List中的数据是有序可重复的,因此可以通过下标获取一个或者一段数据Set存储字符串类型的集合数据,Set中的数据是无序的且不可重复Sorted Set存储不可重复的字符串数据,但是区别于Set的是,Sorted Set可以在存储数据时手动设置一个排序值,以此作为排序依据
数据库选择
有16个库,从0–15,默认是0号库,库的选择:select 库号;不同库的数据不影响
select 0-15 选择库flushall清空整个redis服务器数据,所有的数据库全部清空flushdb清除当前库
数据操作
String
| 命令 | 语法 | 用途 | 示例 |
|---|---|---|---|
| set | set 键 值 | 保存一个键值对,键存在则覆盖值 | set test 10 |
| get | get 键 | 通过键取出对应的值,如果键不存在则返回null | get test |
| getset | getset 键 值 | 先取出键对应的值,然后修改值 | getset test 10 20 |
| incr | incr 键 | 将键对应值自增1 | ncr test |
| decr | decr 键 | 将键对应值自减1 | decr test |
| incrby | incrby 键 自增值 | 将该键对应的值自增指定数值 | incrby test 20 |
| decrby | decrby 键 自减值 | 将该键对应的值自减指定数值 | decrby test 10 |
| append | append 键 值 | 如果该键存在,则在该值得基础上追加一段字符串,如果不存在该键则新增一个键值对 | append test 66 |
1 | 127.0.0.1:6379> expire key 60 # 数据在 60s 后过期 |
Hash
| 命令 | 语法 | 用途 | 示例 |
|---|---|---|---|
| hset | hset 键 属性名 值 | 为指定的键所对应的hash数据中的某个属性赋值 | hset student name jack |
| hmset | hset 键 属性名1 值1 属性名2 值2 。。。 | 向指定的键所对应的hash数据中一次保存一个或者多个键值对数据 | |
| hget | hget 键 属性名 | 查询指定键对应的hash数据中某个属性的值 | hget student name 结果:jack |
| hmget | hmget 键 属性名1 属性名2 。。。 | 查询指定键对应的hash数据中一个或多个键值对的值 | |
| hdel | hdel 键 属性名1 属性名2 。。。 | 删除指定键对应的hash数据中的一个或者多个属性 | lrange names 0 10 结果是names对应的集合中0-10之间的数据,如果数据长度不足,则返回已有的数据,不会出现异常 |
| hexists | hexists 键 属性 | 判断指定键中是否存在某个属性,返回1表示存在,0表示不存在 | hexists student name |
| hlen | hlen 键 | 返回指定键对应的hash数据的属性个数 | |
| hkeys | hkeys 键 | 返回指定键对应的hash数据中的所有属性名称 | |
| hvals | hvals 键 | 返回指定键对应的hash数据中的所有属性值 | |
| hincrby | hincrby 键 属性名称 增量 | 将指定键对应的属性值自增增量的值 | hincrby student age 10 age的值在原本的基础上+10 |
List
| 命令 | 语法 | 用途 | 示例 |
|---|---|---|---|
| lpush | lpush 键 值1 值2… | 在指定的键所对应的list的头部插入所有的values,键不存在则新增 | lpush names jack rose 集合中最前的两个数据是rose jack |
| rpush | rpush 键 值1 值2… | 在指定的键所对应的list的尾部插入所有的values,键不存在则新增 | rpush names jack rose 集合中最后的两个数据是jack rose |
| lrange | lrange 键 下标1 下标2 | 查询从下标1到下标2之间的数据,第一个数据下标为0,下标可以为负数,-1表示倒数第一个数据,-2表示倒数第二个数据,以此类推 | lrange names 0 10 结果是names对应的集合中0-10之间的数据,如果数据长度不足,则返回已有的数据,不会出现异常 |
| lpushx | lpushx键 值1 | 在指定的键存在的情况下,将所有的数据插入到集合的头部 | lpushx names jack rose 集合中最前的两个数据是rose jack |
| rpushx | rpushx键 值1 | 在指定的键存在的情况下,将所有的数据插入到集合的尾部 | rpush names jack rose 集合中最后的两个数据是jack rose |
| lpop | lpop 键 | 将该键对应的集合中的第一个数据取出,取出之后第一个数据就从集合中移除 | lpop names 结果:取出并移除第一个数据 |
| rpop | rpop键 | 将该键对应的集合中的最后一个个数据取出,取出之后数据就从集合中移除 | rpop names 结果:取出并移除最后一个数据 |
通过 rpush/lpop 实现队列
1 | 127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素 |
通过 rpush/rpop 实现栈
1 | 127.0.0.1:6379> rpush myList2 value1 value2 value3 |

通过 lrange 查看对应下标范围的列表元素
1 | 127.0.0.1:6379> rpush myList value1 value2 value3 |
通过 lrange 命令,你可以基于 list 实现分页查询,性能非常高!
通过 llen 查看链表长度
1 | 127.0.0.1:6379> llen myList |
Set
| 命令 | 语法 | 用途 | 示例 |
|---|---|---|---|
| sadd | add 键 值1 值2… | 在指定的键对应的set集合中保存一个或多个数据 | sadd names jack tom 集合中最前的两个数据是rose jack |
| smembers | smembers键 | 查询指定键的Set集合中保存的所有数据 | smembers names |
| scard | scard键 | 查询指定键的Set集合中保存的数据个数 | scard names |
| sismember | sismembe 键 值 | 判断值是否是指定键对应的Set集合中的成员,返回1表示是,0表示否 | sismember names jack |
| srem | srem键 值1 值2… | 删除指定键对应的Set集合中的一个或多个数据 | srem names jack |
| spop | spop键 count | 随机删除并返回指定键对应的Set集合中的1个或多个数据,数量由count决定,但是在某些版本中count不支持,不提供count时默认count为1 | spop numbers |
| srandmember | srandmember键 count | 随机返回指定键对应的Set集合中的1个或多个数据,数量由count决定,不提供count时默认count为1 | srandmember names 2 随机返回names集合中的2个数据 |
| smove | smove 键1 键2 值 | 将键1对应集合中的指定数据移动到键2的集合中 | smove names1 names2 jack |
| sdiff | sdiff 键1 键2 | 返回键1的集合中在键2的集合中不存在的数据,也就是求键1集合在键2集合中的差集 | sdiff names1 names2 |
| sdiffstore | sdiffstore 键1 键2 键3 | 将键2集合在键3中的差集保存到键1的集合中 | sdiffstore names names1 names2 |
| sinter | sinter 键1 键2 | 返回键1集合中在键2集合中也存在的数据,也就是求键1集合和键2集合的交集 | sinter names1 names2 |
| sinterstore | sinterstore 键1 键2 键3 | 将键2集合在键3中的交集保存到键1的集合中 | sinterstore names names1 names2 |
| sunion | sunion 键1 键2 | 返回键1集合和键2集合的并集 | sunion names1 names2 |
| sunionstore | sunion 键1 键2 键3 | 将键2集合和键3集合的并集保存到键1集合中 | sunionstore names names1 names2 |
SortSet
| 命令 | 语法 | 用途 | 示例 |
|---|---|---|---|
| zadd | zadd 键 score value score value … | 向指定键对应的集合中添加数据,score为排序值,可以是整数或小数。value为值 | zadd names 1 zhangsan 2 lisi |
| zcard | zcard键 | 返回指定键对应的集合中的数据总数 | zcard names |
| zcount | zcount 键 min max | 查询指定键的集合中排序值在min和max之间的数据个数 | zcount names 1 5 |
| zrange | zrange键 start stop | 返回指定键对应的集合中排序序号(非排序值)在start和stop之间的数据,序号从0开始,数据会升序排列 | zrange names jack |
| zrank | zrank 键 值 | 返回指定键对应的集合中某个值得排序序号 | zrank names jack |
| zrem | zrem 键1 值1 值2 | 移除指定键对应的Set集合中的1个或多个值 | zrem names1 jack |
| zremrangebyrank | zremrangebyrank 键 start stop | 按照排序序号移除多个成员 | zremrangebyrank names 0 2 |
| zremrangebyscore | zremrangebyscore键 min max | 按照排序值移除多个成员 | zremrangebyscore names 1 2 |
事务
虽然redis是单线程,但是可以同时有多个客户端访问,每个客户端会有一个线程。客户端访问之间存在竞争,redis里面只有单个命令是执行的。比如set,get。每执行一个命令都需要客户端来竞争,所以可能出现并发问题,如果你希望把一组命令执行的结果作为整体,要么全部成功,要么失败,就必须用锁,或者事务
开启:multi
1 | 127.0.0.1:6379> multi |
提交:exec
1 | 127.0.0.1:6379> exec |
清除待执行队列:discard
监听:watch类似乐观锁,
如果在
watch命令观测一个key之后,开启事务后修改该key.这个时候如果有其它连接修改了key,则会导致事务执行失败,在这个事务的其他操作也是失败
exec之后,watch命令监控取消watch命令可以说是redis的事务功能最关键的运用了,在使用了watch之后可以保证一定的原子性和数据安全
特点
没有隔离级别的概念
开启事务之后的操作全部是在待执行队列中缓存,并没有真正执行,也就不存在事务内部的查询要看到事务即将的更新,事务外部也不知道
不保证原子性
Redis对单条命令是保证原子性(比如批量msetnx命令),但是如果事务不保证原子性(一致性),就没有回滚的概念了.事务中任何命令的失败,其余命令任会执行
可以这么说.Redis的以上两个事务特征几乎可以认为,redis没有事务功能.更应该称之为命令的打包执行.
那么为什么redis中要有事务?举个例子:假设登录的时候记录登录的ip(一条命令操作),接下再执行保存用户的登录消息操作(一条命令),假设获取用户的消息需要在另外一个系统中获取,我们无法保证100%获取到.但是这两步操作在我们程序业务功能设计中应该被认为是登录操作的单个功能起的影响.因为获取用户的登录消息可能会失败.那么就没必要记录ip了.redis恰恰提供事务名队列的清空功能
可以怎么理解,如果你的(命令)操作步骤非常多,每一个命令都需要大量的其他非redis的操作才能保证接下来的业务进行,那么就需要redis的事务队列功能一步一步记录命令,在整个工程中如果发生了意外则清空队列,正常则提交
所以我们应该在我们的程序代码中保证一致性和隔离级别的功能而不是交给redis,方正redis的事务就是打包执行,任何利用是查询设计的问题
在redis开启事务的魅力multi就可以知道,redis自己本身也没有把这个功能称之为事务.正确的叫法是多命令
若在待执行队列中存在语法性错误,exec提交之后,其他正确命令也会被执行,这是单单的错误命令抛出异常
1 | 127.0.0.1:6379> multi |
如果是错误的命令名(比如
setnx写成setnn,则不能称之为语法错误),如果在队列中出现了类似错误,则整个队列不成功
持久化
概念
解决计算机关闭造成的内存数据丢失问题
RDB(Redis DataBase)
redis默认采用此快照方式对数据进行持久化操作
Redis 快照 是最简单的 Redis 持久性模式。当满足特定条件时,它将生成数据集的时间点快照,例如,如果先前的快照是在2分钟前创建的,并且现在已经至少有 100 次新写入,则将创建一个新的快照。此条件可以由用户配置 Redis 实例来控制,也可以在运行时修改而无需重新启动服务器。快照作为包含整个数据集的单个 .rdb 文件生成。
AOF(append-only file)
快照不是很持久。如果运行 Redis 的计算机停止运行,电源线出现故障或者您 kill -9 的实例意外发生,则写入 Redis 的最新数据将丢失。尽管这对于某些应用程序可能不是什么大问题,但有些使用案例具有充分的耐用性,在这些情况下,快照并不是可行的选择。
AOF(Append Only File - 仅追加文件) 它的工作方式非常简单:每次执行 修改内存 中数据集的写操作时,都会 记录 该操作。假设 AOF 日志记录了自 Redis 实例创建以来 所有的修改性指令序列,那么就可以通过对一个空的 Redis 实例 顺序执行所有的指令,也就是 「重放」,来恢复 Redis 当前实例的内存数据结构的状态
AOF 重写
Redis 在长期运行的过程中,AOF 的日志会越变越长。如果实例宕机重启,重放整个 AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 **AOF 日志 “瘦身”**。
Redis 提供了
bgrewriteaof指令用于对 AOF 日志进行瘦身。其 原理 就是 开辟一个子进程 对内存进行 遍历 转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件 中。序列化完毕后再将操作期间发生的 增量 AOF 日志 追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
fsync
AOF 日志是以文件的形式存在的,当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回到磁盘的。
就像我们 上方第四步 描述的那样,我们需要借助
glibc提供的fsync(int fd)函数来讲指定的文件内容 强制从内核缓存刷到磁盘。但 “强制开车” 仍然是一个很消耗资源的一个过程,需要 **”节制”**!通常来说,生产环境的服务器,Redis 每隔 1s 左右执行一次fsync操作就可以了。Redis 同样也提供了另外两种策略,一个是 **永不
fsync**,来让操作系统来决定合适同步磁盘,很不安全,另一个是 来一个指令就fsync一次,非常慢。但是在生产环境基本不会使用,了解一下即可。
设置
- 新增配置文件
- 使用
cat redis.conf | grep -v "#" | grep -v "^$" > redis7379.conf命令将配置文件的注释去掉并放入另外一个配置文件
- 使用
- 修改配置文件参数
bind0.0.00- 允许所有IP连接
port7379- 端口,自定义,根据需要自定义
pidfile/var/run/redis_7379.pid- 进程号信息,自定义
logfile“/root/redis-6.0.6/redis_7379.log”- 日志文件,自定义
- 将三个save注释掉,因为不打算采用RDB方式进行持久化
appendonlyyes- 开启AOF持久化
appendfilename“appendonly7379.aof”- 持久化文件名
appendfsynceverysec- 主要有三个参数可以选择:always、everysec和no。设置为always时,会极大消弱Redis的性能,因为这种模式下每次write后都会调用fsync(Linux为调用fdatasync;如果设置为no,则write后不会有fsync调用,由操作系统自动调度刷磁盘,性能是最好的;everysec为最多每秒调用一次fsync,这种模式性能并不是很糟糕,一般也不会产生毛刺,这归功于Redis引入了BIO线程,所有fsync操作都异步交给了BIO线程。
集群
主从复制
启动多个redis,启动默认都是为主节点
通过启动不同的redis配置文件达到此目的,可以通过bash命令批量执行这些命令
1
2
3
4
./../src/redis-server /root/redis-6.0.6/config/redis7379.conf &
./../src/redis-server /root/redis-6.0.6/config/redis7380.conf &
./../src/redis-server /root/redis-6.0.6/config/redis7381.conf &
1
将主节点变成从节点,使用
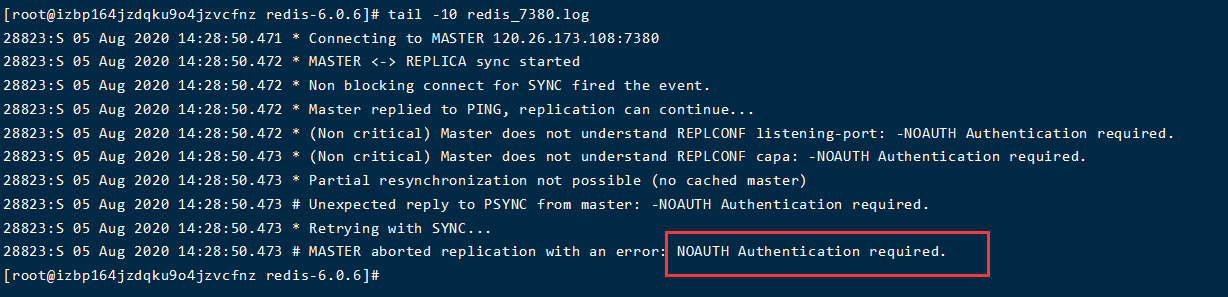
slaveof命令- 进入 Redis 实例中使用控制台
PS D:\soft_green_store\redisbin64> ./redis-cli.exe -p 7380 -h 120.26.173.108 -a jungle123456
slaveof 120.26.173.108 7380- 注意:在主库没有设置
requirepass要求密码验证的情况下,主库已设置则从库需额外在配置文件中加上masterauth 主库密码参数才可以复制主库的数据![]()
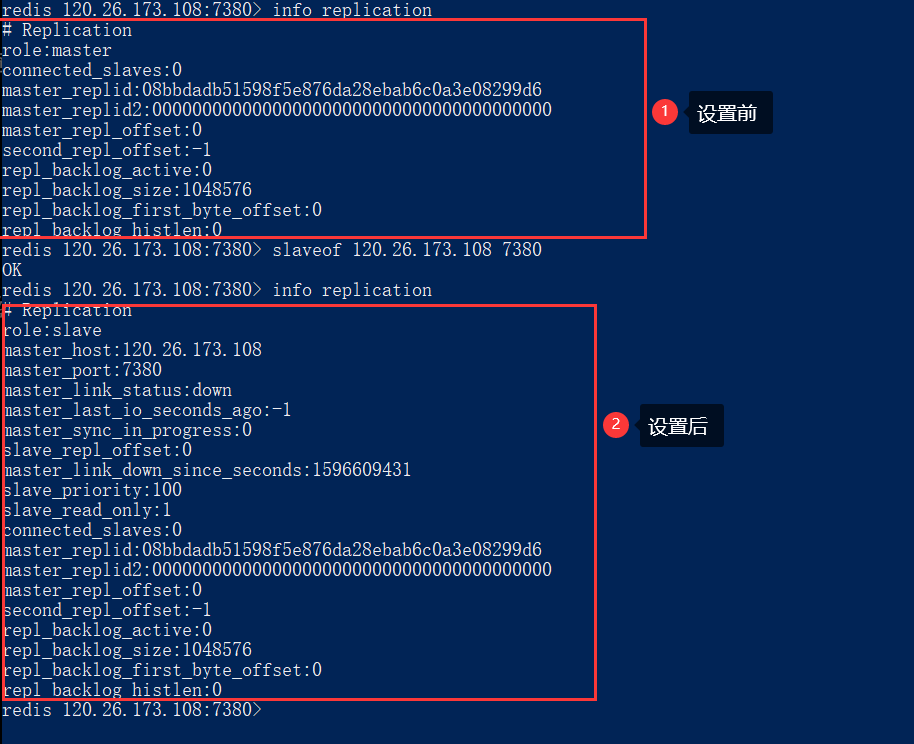
- 通过
info replication可以查看redis相关状态信息![]()
- 注意:在主库没有设置
- 进入 Redis 实例中使用控制台
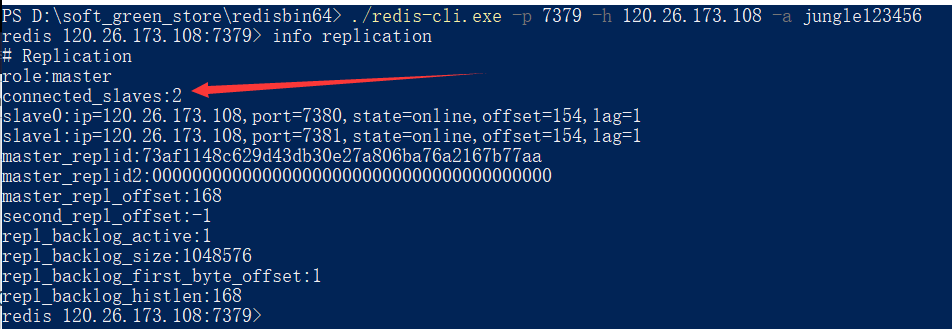
搭建完成
![]()
Redis Sentinel哨兵
复制几分哨兵的配置文件出来
1
2
3
4
5
6
7
8port 26379 #哨兵端口
daemonize yes #后台守护
logfile "/root/redis-6.0.6/config/sentinel_log/26379.log" #日志文件
#mymaster这个名字是自己给的别名,还是系统默认?? 名字监听ip+端口 选举次数要到达2次
sentinel monitor mymaster 120.26.173.108 7379 2
sentinel auth-pass mymaster jungle123456 #监听密码
sentinel down-after-milliseconds mymaster 10000 #监听服务GG等待时间
#应该还应该配置哨兵的密码!!!生产环境增加bash命令
1
2
3
4
5
6
7
8
9
#启动redis主从
./../src/redis-server /root/redis-6.0.6/config/redis7379.conf &
./../src/redis-server /root/redis-6.0.6/config/redis7380.conf &
./../src/redis-server /root/redis-6.0.6/config/redis7381.conf &
#启动哨兵,哨兵启动后,哨兵配置文件,还会发现出现了一些变化
./../src/redis-server /root/redis-6.0.6/config/sentin1.conf --sentinel
./../src/redis-server /root/redis-6.0.6/config/sentin2.conf --sentinel
./../src/redis-server /root/redis-6.0.6/config/sentin3.conf --sentinel测试
使用
redis-cil工具连接哨兵节点,并执行info Sentinel命令来查看是否已经在监视主节点了:1
2
3
4
5
6
7
8
9PS D:\soft_green_store\redisbin64> ./redis-cli.exe -p 26379 -h 120.26.173.108
redis 120.26.173.108:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=120.26.173.108:7379,slaves=0,sentinels=3上面打印的信息显示出,一个主节点下并没有子slaves节点,说明启动的三个redis服务,另外两个并没有成为子服务,因为之前是通过启动后再通过命令来将主节点变成子节点,这里觉得太麻烦,果断修改配置文件,加上
slaveof 120.26.173.108 7379,再重启启动,就一切ok了,全部配置如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
jemalloc-bg-thread yes
masterauth jungle123456
slaveof 120.26.173.108 7379再测试kill掉主节点后的变化
1
2
3
4
5
6
7
8# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=120.26.173.108:7380,slaves=2,sentinels=3
redis 120.26.173.108:26379>但同时还可以发现,哨兵节点认为新的主节点仍然有两个从节点 *(上方 slaves=2)*,这是因为哨兵在将
6381切换成主节点的同时,将6379节点置为其从节点。虽然6379从节点已经挂掉,但是由于 哨兵并不会对从节点进行客观下线,因此认为该从节点一直存在。当6379节点重新启动后,会自动变成6381节点的从节点。
另外,在故障转移的阶段,哨兵和主从节点的配置文件都会被改写:
- 对于主从节点: 主要是
slaveof配置的变化,新的主节点没有了slaveof配置,其从节点则slaveof新的主节点。 - 对于哨兵节点: 除了主从节点信息的变化,纪元(epoch) (记录当前集群状态的参数) 也会变化,纪元相关的参数都 +1 了。
那么,问题就来了,3个哨兵,不小心挂了两个,选举又要求有2个,这样的情况又如何解决呢?
搜索了一下,没人提这个东西,是需要哨兵之间搭一个集群,还是这个方案没人用,所以没人care。Q。。。AQ。。。
Redis集群
注:本文很多理论内容都是来自这里,特别是下面的内容,几乎一模一样,主要目的是防止原文消失QAQ
上图 展示了 Redis Cluster 典型的架构图,集群中的每一个 Redis 节点都 互相两两相连,客户端任意 直连 到集群中的 任意一台,就可以对其他 Redis 节点进行 读写 的操作。
基本原理
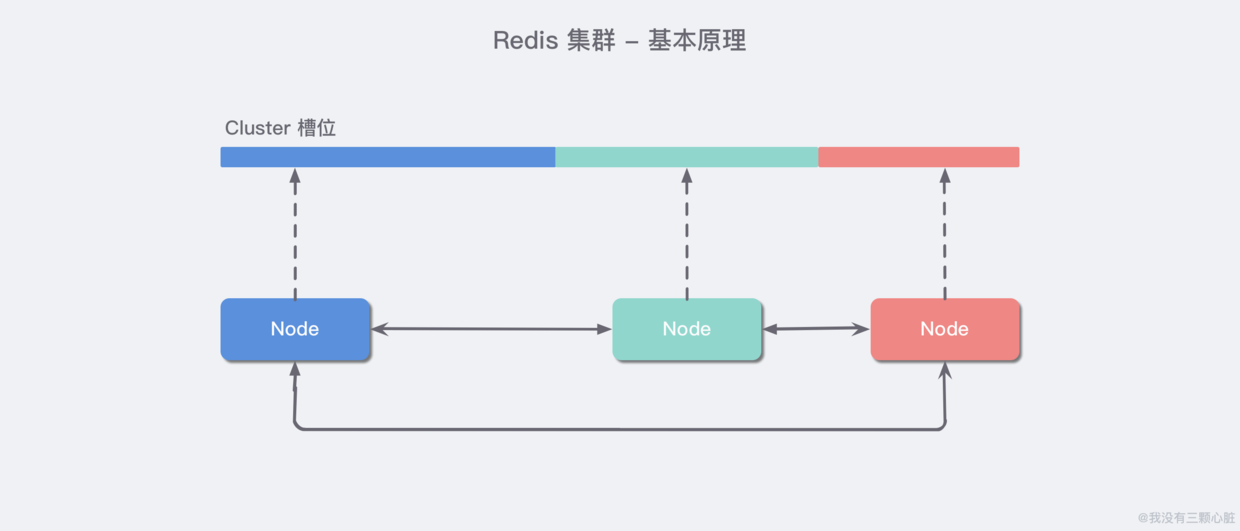
Redis 集群中内置了 16384 个哈希槽。当客户端连接到 Redis 集群之后,会同时得到一份关于这个 集群的配置信息,当客户端具体对某一个 key 值进行操作时,会计算出它的一个 Hash 值,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,Redis 会根据节点数量 大致均等 的将哈希槽映射到不同的节点。
再结合集群的配置信息就能够知道这个 key 值应该存储在哪一个具体的 Redis 节点中,如果不属于自己管,那么就会使用一个特殊的 MOVED 命令来进行一个跳转,告诉客户端去连接这个节点以获取数据:
1 | GET x |
MOVED 指令第一个参数 3999 是 key 对应的槽位编号,后面是目标节点地址,MOVED 命令前面有一个减号,表示这是一个错误的消息。客户端在收到 MOVED 指令后,就立即纠正本地的 槽位映射表,那么下一次再访问 key 时就能够到正确的地方去获取了。
集群的主要作用
- 数据分区: 数据分区 (或称数据分片) 是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。Redis 单机内存大小受限问题,在介绍持久化和主从复制时都有提及,例如,如果单机内存太大,
bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出…… - 高可用: 集群支持主从复制和主节点的 自动故障转移 (与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。
快速体验
第一步:创建集群节点配置文件
首先我们找一个地方创建一个名为 redis-cluster 的目录:
1 | mkdir -p ~/Desktop/redis-cluster |
然后按照上面的方法,创建六个配置文件,分别命名为:redis_7000.conf/redis_7001.conf…..redis_7005.conf,然后根据不同的端口号修改对应的端口值就好了:
1 | # 绑定ID地址,记得换成自己服务器 |
记得把对应上述配置文件中根端口对应的配置都修改掉 *(port/ pidfile/ cluster-config-file)*。
Jungle:
sed -i "s/7001/7006/g"grep “7001” -rl ./redis_7006.conf``可以批量将文件内的内容替换
第二步:分别启动 6 个 Redis 实例
1 | redis-server ~/Desktop/redis-cluster/redis_7000.conf |
然后执行 ps -ef | grep redis 查看是否启动成功:
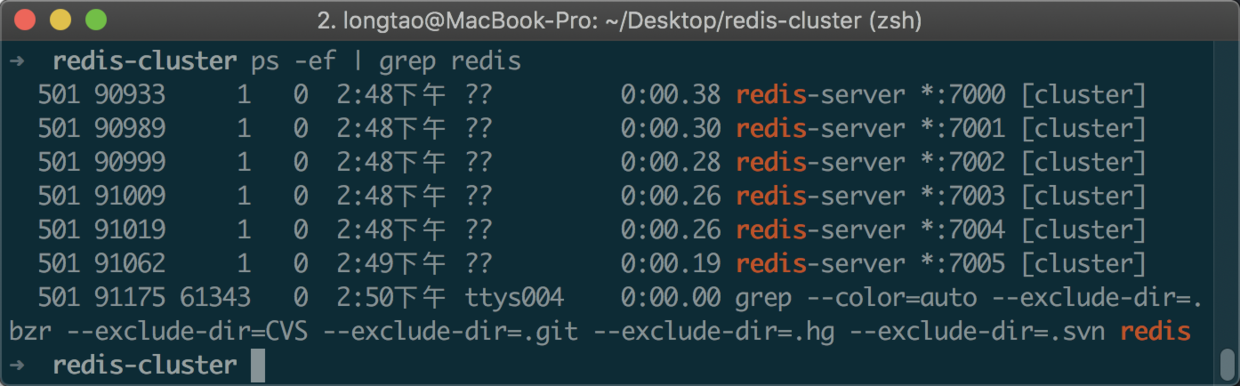
可以看到 6 个 Redis 节点都以集群的方式成功启动了,但是现在每个节点还处于独立的状态,也就是说它们每一个都各自成了一个集群,还没有互相联系起来,我们需要手动地把他们之间建立起联系。
第三步:建立集群
执行下列命令:
1 | redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 |
Jungle:
运行了
1
./../../src/redis-cli --cluster create --cluster-replicas 1 120.26.173.108:7000 120.26.173.108:7001 120.26.173.108:7002 120.26.173.108:7003 120.26.173.108:7004 120.26.173.108:7005
出现[ERR] Node 120.26.173.108:7000 DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password is requested to clients一大串红色。
我估计就是因为配置文件没有设置
protected-mode false,系统默认给了true,这时候可以选择给个false,或者给个密码 -a 密码../src/redis-cli –cluster create –cluster-replicas 1 -a 1Jiangguopanzer! 119.91.255.95:6379 119.91.255.95:6380 119.91.255.95:6381 119.91.255.95:6383 119.91.255.95:6384 119.91.255.95:6385
再次运行,一直出现
Waiting for the cluster to join...............................................原因是端口没有放行,这里使用的是7001到7005,那么7001-7005及17001-17005都要放行
*因为是云服务器,连接到redis时,redis之间是通过redis内网,所以可以在集群创建后,修改产生的node.config,将里面的内网ID修改为公网,再重新启动redis
这里稍微解释一下这个
--replicas 1的意思是:我们希望为集群中的每个主节点创建一个从节点。
观察控制台输出:
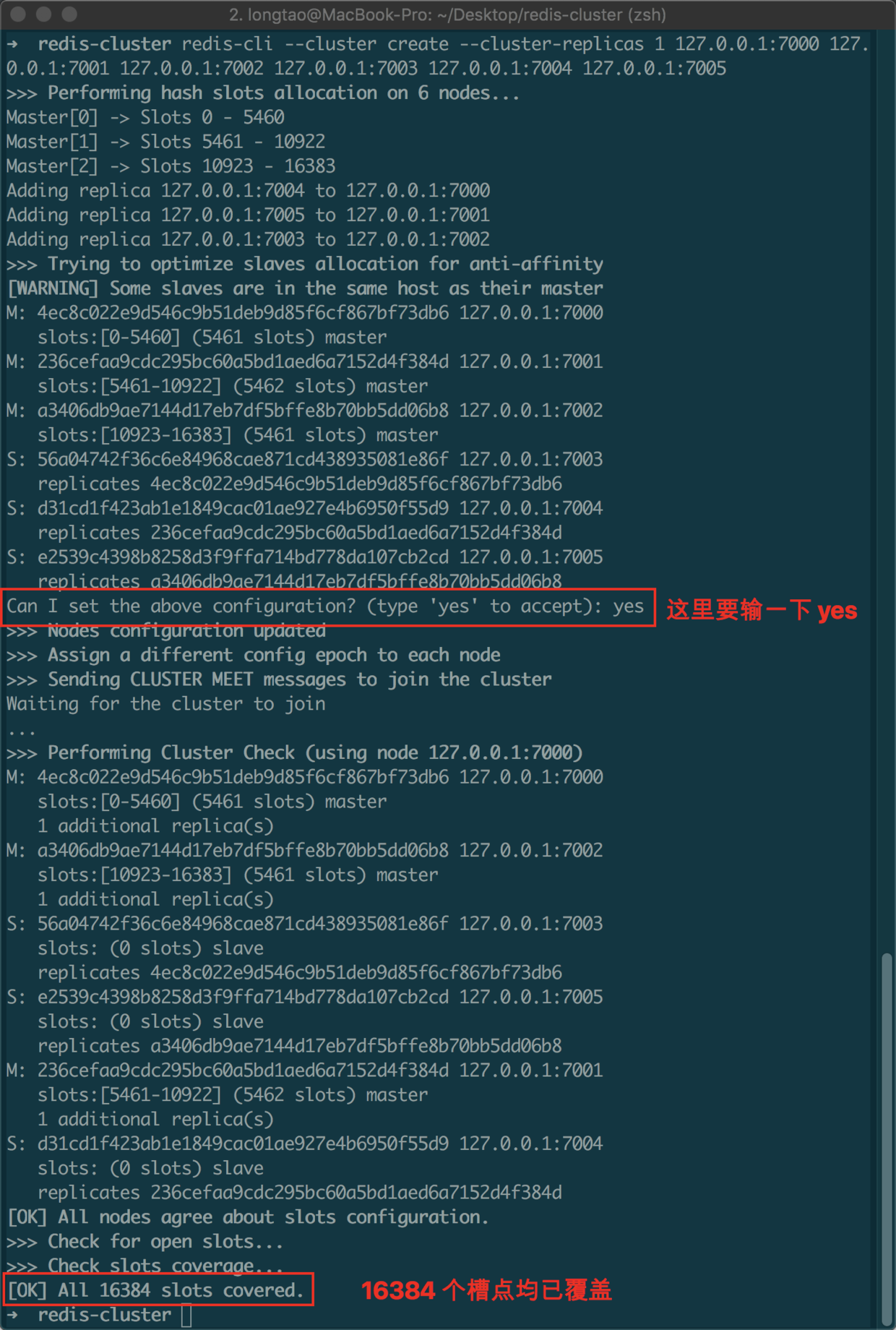
看到 [OK] 的信息之后,就表示集群已经搭建成功了,可以看到,这里我们正确地创建了三主三从的集群。
第四步:验证集群
我们先使用 redic-cli 任意连接一个节点:
1 | redis-cli -c -h 119.91.255.95 -p 6379 -a 1Jiangguopanzer! |
-c表示集群模式;-h指定 ip 地址;-p指定端口。
然后随便 set 一些值观察控制台输入:
1 | 127.0.0.1:7000> SET name wmyskxz |
可以看到这里 Redis 自动帮我们进行了 Redirected 操作跳转到了 7001 这个实例上。
我们再使用 cluster info (查看集群信息) 和 cluster nodes (查看节点列表) 来分别看看:*(任意节点输入均可)*
1 | 127.0.0.1:7001> CLUSTER INFO |
数据分区方案简析
方案一:哈希值 % 节点数
哈希取余分区思路非常简单:计算 key 的 hash 值,然后对节点数量进行取余,从而决定数据映射到哪个节点上。
不过该方案最大的问题是,当新增或删减节点时,节点数量发生变化,系统中所有的数据都需要 重新计算映射关系,引发大规模数据迁移。
方案二:一致性哈希分区
一致性哈希算法将 整个哈希值空间 组织成一个虚拟的圆环,范围是 *[0 , 232-1]*,对于每一个数据,根据 key 计算 hash 值,确数据在环上的位置,然后从此位置沿顺时针行走,找到的第一台服务器就是其应该映射到的服务器:
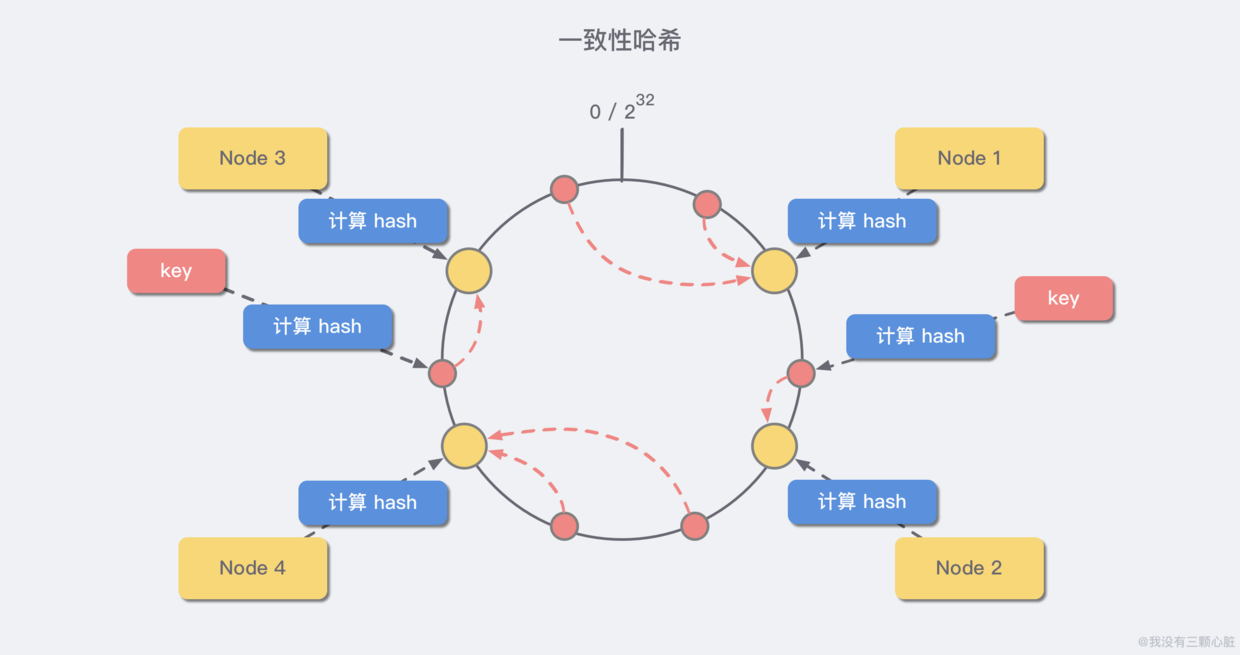
与哈希取余分区相比,一致性哈希分区将 增减节点的影响限制在相邻节点。以上图为例,如果在 node1 和 node2 之间增加 node5,则只有 node2 中的一部分数据会迁移到 node5;如果去掉 node2,则原 node2 中的数据只会迁移到 node4 中,只有 node4 会受影响。
一致性哈希分区的主要问题在于,当 节点数量较少 时,增加或删减节点,对单个节点的影响可能很大,造成数据的严重不平衡。还是以上图为例,如果去掉 node2,node4 中的数据由总数据的 1/4 左右变为 1/2 左右,与其他节点相比负载过高。
方案三:带有虚拟节点的一致性哈希分区
该方案在 一致性哈希分区的基础上,引入了 虚拟节点 的概念。Redis 集群使用的便是该方案,其中的虚拟节点称为 槽(slot)。槽是介于数据和实际节点之间的虚拟概念,每个实际节点包含一定数量的槽,每个槽包含哈希值在一定范围内的数据。
在使用了槽的一致性哈希分区中,槽是数据管理和迁移的基本单位。槽 解耦 了 数据和实际节点 之间的关系,增加或删除节点对系统的影响很小。仍以上图为例,系统中有 4 个实际节点,假设为其分配 16 个槽(0-15);
- 槽 0-3 位于 node1;4-7 位于 node2;以此类推….
如果此时删除 node2,只需要将槽 4-7 重新分配即可,例如槽 4-5 分配给 node1,槽 6 分配给 node3,槽 7 分配给 node4;可以看出删除 node2 后,数据在其他节点的分布仍然较为均衡。
节点通信机制简析
集群的建立离不开节点之间的通信,例如我们上访在 快速体验 中刚启动六个集群节点之后通过 redis-cli 命令帮助我们搭建起来了集群,实际上背后每个集群之间的两两连接是通过了 CLUSTER MEET <ip> <port> 命令发送 MEET 消息完成的,下面我们展开详细说说。
两个端口
在 哨兵系统 中,节点分为 数据节点 和 哨兵节点:前者存储数据,后者实现额外的控制功能。在 集群 中,没有数据节点与非数据节点之分:所有的节点都存储数据,也都参与集群状态的维护。为此,集群中的每个节点,都提供了两个 TCP 端口:
- 普通端口: 即我们在前面指定的端口 *(7000等)*。普通端口主要用于为客户端提供服务 (与单机节点类似);但在节点间数据迁移时也会使用。
- 集群端口: 端口号是普通端口 + 10000 (10000是固定值,无法改变),如
7000节点的集群端口为17000。集群端口只用于节点之间的通信,如搭建集群、增减节点、故障转移等操作时节点间的通信;不要使用客户端连接集群接口。为了保证集群可以正常工作,在配置防火墙时,要同时开启普通端口和集群端口。
Gossip 协议
节点间通信,按照通信协议可以分为几种类型:单对单、广播、Gossip 协议等。重点是广播和 Gossip 的对比。
- 广播是指向集群内所有节点发送消息。优点 是集群的收敛速度快(集群收敛是指集群内所有节点获得的集群信息是一致的),缺点 是每条消息都要发送给所有节点,CPU、带宽等消耗较大。
- Gossip 协议的特点是:在节点数量有限的网络中,每个节点都 “随机” 的与部分节点通信 (并不是真正的随机,而是根据特定的规则选择通信的节点)*,经过一番杂乱无章的通信,每个节点的状态很快会达到一致。Gossip 协议的 优点 有负载 *(比广播) 低、去中心化、容错性高 (因为通信有冗余) 等;缺点 主要是集群的收敛速度慢。
消息类型
集群中的节点采用 固定频率(每秒10次) 的 定时任务 进行通信相关的工作:判断是否需要发送消息及消息类型、确定接收节点、发送消息等。如果集群状态发生了变化,如增减节点、槽状态变更,通过节点间的通信,所有节点会很快得知整个集群的状态,使集群收敛。
节点间发送的消息主要分为 5 种:meet 消息、ping 消息、pong 消息、fail 消息、publish 消息。不同的消息类型,通信协议、发送的频率和时机、接收节点的选择等是不同的:
- MEET 消息: 在节点握手阶段,当节点收到客户端的
CLUSTER MEET命令时,会向新加入的节点发送MEET消息,请求新节点加入到当前集群;新节点收到 MEET 消息后会回复一个PONG消息。 - PING 消息: 集群里每个节点每秒钟会选择部分节点发送
PING消息,接收者收到消息后会回复一个PONG消息。PING 消息的内容是自身节点和部分其他节点的状态信息,作用是彼此交换信息,以及检测节点是否在线。PING消息使用 Gossip 协议发送,接收节点的选择兼顾了收敛速度和带宽成本,具体规则如下:(1)随机找 5 个节点,在其中选择最久没有通信的 1 个节点;(2)扫描节点列表,选择最近一次收到PONG消息时间大于cluster_node_timeout / 2的所有节点,防止这些节点长时间未更新。 - PONG消息:
PONG消息封装了自身状态数据。可以分为两种:第一种 是在接到MEET/PING消息后回复的PONG消息;第二种 是指节点向集群广播PONG消息,这样其他节点可以获知该节点的最新信息,例如故障恢复后新的主节点会广播PONG消息。 - FAIL 消息: 当一个主节点判断另一个主节点进入
FAIL状态时,会向集群广播这一FAIL消息;接收节点会将这一FAIL消息保存起来,便于后续的判断。 - PUBLISH 消息: 节点收到
PUBLISH命令后,会先执行该命令,然后向集群广播这一消息,接收节点也会执行该PUBLISH命令。
数据结构简析
节点需要专门的数据结构来存储集群的状态。所谓集群的状态,是一个比较大的概念,包括:集群是否处于上线状态、集群中有哪些节点、节点是否可达、节点的主从状态、槽的分布……
节点为了存储集群状态而提供的数据结构中,最关键的是 clusterNode 和 clusterState 结构:前者记录了一个节点的状态,后者记录了集群作为一个整体的状态。
clusterNode 结构
clusterNode 结构保存了 一个节点的当前状态,包括创建时间、节点 id、ip 和端口号等。每个节点都会用一个 clusterNode 结构记录自己的状态,并为集群内所有其他节点都创建一个 clusterNode 结构来记录节点状态。
下面列举了 clusterNode 的部分字段,并说明了字段的含义和作用:
1 | typedef struct clusterNode { |
除了上述字段,clusterNode 还包含节点连接、主从复制、故障发现和转移需要的信息等。
clusterState 结构
clusterState 结构保存了在当前节点视角下,集群所处的状态。主要字段包括:
1 | typedef struct clusterState { |
除此之外,clusterState 还包括故障转移、槽迁移等需要的信息。
建议阅读
配置
阅读文章
概念
https://blog.csdn.net/nsrainbow/article/details/49032337
文章这里配置不错
1 | bind:0.0.0.0(指定访问的网卡,默认为127.0.01只能本机访问,可以将此项改为0.0.0.0或本机IP,或者直接注释掉此项。) |
缓存
缓存穿透
概念
大量请求的key不存在缓存中,导致请求全部落在数据库
解决方式
参数校验,hibenate官网文档
ID校验
邮箱格式不对
参考文章参考文章 Validated代表去实体类校验 <1> 参数 Foo 前需要加上 @Validated 注解,表明需要 spring 对其进行校验,而校验的信息会存放到其后的 BindingResult 中。注意,必须相邻,如果有多个参数需要校验,形式可以如下。foo(@Validated Foo foo, BindingResult fooBindingResult ,@Validated Bar bar, BindingResult barBindingResult); 即一个校验类对应一个校验结果。 <2> 校验结果会被自动填充,在 controller 中可以根据业务逻辑来决定具体的操作,如跳转到错误页面。 #JSR 提供的校验注解 @Null 被注释的元素必须为 null @NotNull 被注释的元素必须不为 null @AssertTrue 被注释的元素必须为 true @AssertFalse 被注释的元素必须为 false @Min(value) 被注释的元素必须是一个数字,其值必须大于等于指定的最小值 @Max(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 @DecimalMin(value) 被注释的元素必须是一个数字,其值必须大于等于指定的最小值 @DecimalMax(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 @Size(max=, min=) 被注释的元素的大小必须在指定的范围内 @Digits (integer, fraction) 被注释的元素必须是一个数字,其值必须在可接受的范围内 @Past 被注释的元素必须是一个过去的日期 @Future 被注释的元素必须是一个将来的日期 @Pattern(regex=,flag=) 被注释的元素必须符合指定的正则表达式 #Hibernate Validator @NotBlank(message =) 验证字符串非 null,且长度必须大于 0 @Email 被注释的元素必须是电子邮箱地址 @Length(min=,max=) 被注释的字符串的大小必须在指定的范围内 @NotEmpty 被注释的字符串的必须非空 @Range(min=,max=,message=) 被注释的元素必须在合适的范围内1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
总结:
在springboot中,对于@RequestParam的非实体类参数进行校验,需要在类上加上@Validated注解,BindingRequest参数必须仅跟着实体类参数校验,不能离太远,@validate注解后如果不跟BindingRequest参数,则会抛出异常,不会进入方法内部,其实我也知道,我以后可能不会看这个,但是就是想写一写QAQ......
- 缓存和数据库都没有可以设置过期时间
`set key value EX 10086`但是只能解决key变化不频繁的情况,如要使用此方法,尽量将key的过期时间设置短一点,比如1分钟
注:key的命名:`表名:主键名:主键值`
```java
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
布隆过滤器
布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
具体参考另外一篇详细文章
缓存雪崩
概念
实际上,缓存雪崩描述的就是这样一个简单的场景:缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
举个例子:系统的缓存模块出了问题比如宕机导致不可用。造成系统的所有访问,都要走数据库。
还有一种缓存雪崩的场景是:有一些被大量访问数据(热点缓存)在某一时刻大面积失效,导致对应的请求直接落到了数据库上。 这样的情况,有下面几种解决办法:
举个例子 :秒杀开始 12 个小时之前,我们统一存放了一批商品到 Redis 中,设置的缓存过期时间也是 12 个小时,那么秒杀开始的时候,这些秒杀的商品的访问直接就失效了。导致的情况就是,相应的请求直接就落到了数据库上,就像雪崩一样可怕。
解决方案
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
- 建议阅读:文章1
针对热点缓存失效的情况:
- 设置不同的失效时间比如随机设置缓存的失效时间。
- 缓存永不失效。
JAVA整合
SpringBoot
配置
导包
<!--Redis--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
- 启动器开启缓存,添加`@EnableCaching`注解
- 添加配置文件
- ```yml
spring:
redis:
database: 0
host: 120.26.173.108
port: 7000
#password: jungle123456
#连接超时时间(毫秒)
timeout: 20000
jedis:
pool:
#连接池最大连接数(使用负值表示没有限制)
max-active: 8
#连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: 1
#连接池中的最大空闲连接
max-idle: 8
#连接池中的最小空闲连接
min-idle: 0
cluster:
nodes:
- 120.26.173.108:7000
- 120.26.173.108:7001
- 120.26.173.108:7002
- 120.26.173.108:7003
- 120.26.173.108:7004
- 120.26.173.108:7005
max-redirects: 3
设置一下redis序列化方式
package com.tlm.www.api.config; import org.springframework.cache.CacheManager; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.cache.RedisCacheConfiguration; import org.springframework.data.redis.cache.RedisCacheManager; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.RedisSerializationContext; import java.time.Duration; import java.util.*; import java.util.concurrent.ThreadLocalRandom; /** * Redis 缓存缓存管理器 *1:JdkSerializationRedisSerializer: * * 2:GenericJackson2JsonRedisSerializer * * 3:StringRedisSerializer * * 4:GenericFastJsonRedisSerializer * * 发现只有4:GenericFastJsonRedisSerializer,最好用,不报错 * @author Jiangmanman * @date 2020/08/06 */ @Configuration public class RedisConfig { @Bean public CacheManager cacheManager(RedisConnectionFactory factory) { // 生成一个默认配置,通过config对象即可对缓存进行自定义配置 RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); Integer minuteTime = 10; //设置默认随机时间 int randomIntDefault = 60*minuteTime; OptionalInt firstDefault = ThreadLocalRandom.current().ints(50*minuteTime, (100*minuteTime + 1)).limit(1).findFirst(); boolean presentDefault = firstDefault.isPresent(); if(presentDefault){ randomIntDefault = firstDefault.getAsInt(); } config = config.serializeValuesWith( //设置序列化方式 RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()) ) // 设置缓存的默认过期时间,也是使用Duration设置 .entryTtl(Duration.ofSeconds(randomIntDefault)); // 不缓存空值 // .disableCachingNullValues(); //如何让为null值的缓存时间变成自定义,而不是null值的缓存为固定 // 设置一个初始化的缓存空间set集合 Set<String> cacheNames = new HashSet<>(); cacheNames.add("sys"); //设置自定义空间的随机时间 int randomInt = 20; OptionalInt first = ThreadLocalRandom.current().ints(100, (120 + 1)).limit(1).findFirst(); boolean present = first.isPresent(); if(present){ randomInt = first.getAsInt(); } // 对每个缓存空间应用不同的配置 Map<String, RedisCacheConfiguration> configMap = new HashMap<>(5); configMap.put("view", config.entryTtl(Duration.ofSeconds(randomInt))); // 使用自定义的缓存配置初始化一个cacheManager return RedisCacheManager.builder(factory) // 注意这两句的调用顺序,一定要先调用该方法设置初始化的缓存名,再初始化相关的配置 .initialCacheNames(cacheNames) .withInitialCacheConfigurations(configMap) .cacheDefaults(config) .build(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#### 使用
在业务层层的查询方法上添加`@Cacheable(value = "缓存数据的命名空间名称")`,将查询的数据保存到redis中,后续执行这个业务层方法会优先从缓存中获取数据。
在业务层的增删改方法上添加`@CacheEvict(value="缓存数据的命名空间名称",allEntries = true)`注解,在执行增删改时将缓存数据删除,下次查询时会从数据库查询数据。
属性详细解释如下
Cacheable
- cacheNames:缓存数据的命名空间,可以用于区分不同的数据,其实该值就是缓存数据键的前缀。
- key:定义缓存数据的后缀,可以在同一个命名空间下,对不同的数据进行更加细致的拆分。在key中可以使用#参数名称的方式用参数作为key。
CacheEvict
- cacheNames:需要清除的缓存数据的命名空间
- allEntries:是否需要清空命名空间中所有的数据
一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`
```java
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
例如:
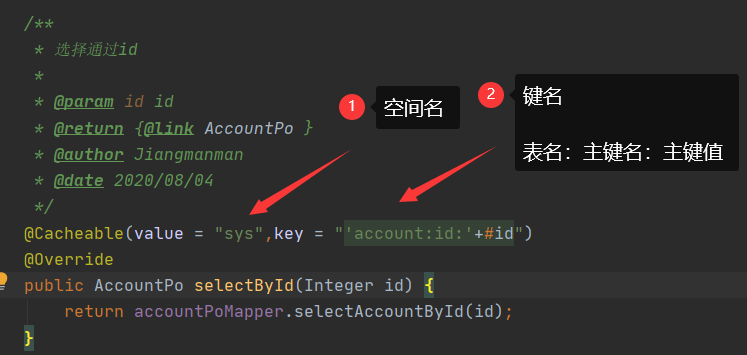
问题解决
springboot集成redis集群,配置文件IP地址为服务器公网ip,控制台日志报错却是服务器内网ip连接不上.
问题原因:整合springboot之后,他会用任意节点通过cluster slots 命令去获取集群中糟点信息,根据控制台报错返回所有节点信息都是内网ip。因为每个节点都是从自己的nodes.conf文件中获取cluster-config-file的地址。集群第一次启动后,会在
cd ./cluster/data/相对应的节点目录下生成该文件,打开该文件会发现cluster-config-file一行的ip地址是自身的内网ip.这是因为生成时自己的的节点ip时通过网卡IP作为地址的,由于云服务器网卡地址是内网,自然这里的ip就是内网的IP地址了。解决方案:
先杀死节点,修改每个节点的nodes.conf中的cluster-config-file,把内网ip改为公网ip;再重启。就OK了(后记:手动将cluster-config-file /root/redis-6.0.6/config/cluster/nodes-7000.conf这个文件里面的内网IP变成公网IP,:1
2
3
4
5#改变命令,每一个都需要改
sed -i "s/172.16.62.141/120.26.173.108/g" `grep "172.16.62.141" -rl ./nodes-7005.conf`
#然后重启
./../../src/redis-server /root/redis-6.0.6/config/cluster/redis_7004.conf
#天呐,要不要这么麻烦!!!)
每个配置文件加上
bind 0.0.0.0重启出现[ERR] Node 120.26.173.108:7000 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
服务器重启前节点中保存了节点配置以及数据备份文件。重启时节点以及数据信息冲突,故无法重启。
删除节点配置(nodes.conf)以及数据备份文件(dump.rdb、appendonly.aof)
清除各节点数据
2.1 连接进入各节点
Linux命令 ./redis-cli -h 192.168.25.133 -p 7001
2.2 清除节点数据
Linux命令 flushdb
偶也,完成所有步骤,springboot测试也成功,将redis的cluster配置备份一下,备份连接如下
链接: https://pan.baidu.com/s/17WQFF-X488Cvx7mEopAmRA 提取码: yka1
JavaRedission整合参考链接